

Qwen2.5-Turbo 炸裂

随着Qwen2.5的发布,阿里巴巴开发团队响应了社区对能够处理更长上下文模型的需求。在过去几个月中,团队对模型进行了多项优化,以提升其在极长上下文中的能力和推理性能。今天,团队自豪地推出了Qwen2.5-Turbo,带来了以下进步:
扩展上下文长度:上下文长度从128k显著增加到1M tokens,大约相当于100万英文单词或150万中文字符。这一容量可以容纳10部完整长度的小说、150小时的语音转录文本或3万行代码。模型在1M-token Passkey Retrieval任务中达到100%的准确率,并在RULER长文本评估基准上得分93.1,超过了GPT-4的91.6和GLM4-9B-1M的89.9。尽管有这些改进,模型在短序列任务上仍保持卓越性能,可与GPT-4o-mini媲美。
更快的推理速度:通过集成稀疏注意力机制,团队将1M-token上下文生成首个token的时间从4.9分钟缩短至仅68秒,实现了4.3倍的加速。
更低的成本:处理成本仍为每1M tokens ¥0.3。以这一价格,Qwen2.5-Turbo可以处理比GPT-4o-mini多3.6倍的tokens,提供更具成本效益的解决方案。
Qwen2.5-Turbo为高效、经济地处理长上下文设定了新标准,同时在各种使用场景中保持高性能。
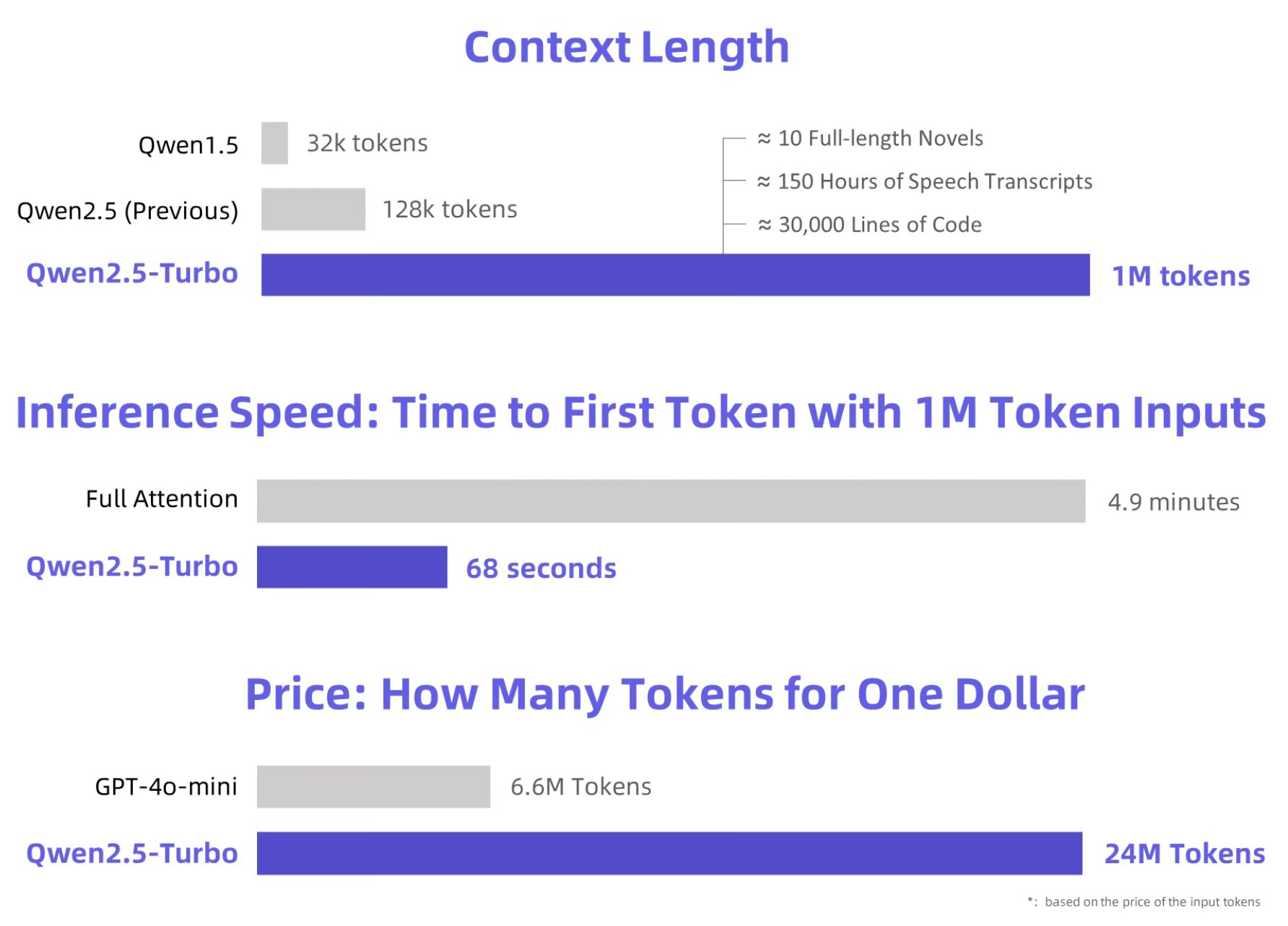
Qwen2.5-Turbo上下文长度
现在,您可以通过阿里云模型工作室的API服务[中文],或通过HuggingFace Demo或ModelScope Demo使用它。
如何使用API
支持1M tokens的Qwen2.5-Turbo模型完全兼容标准Qwen API和OpenAI API。以下是一个简单的Python示例,展示如何使用它。请确保将您的API密钥设置为环境变量YOUR_API_KEY。更多详情,请访问阿里云模型工作室的快速入门(中文)。
import osfrom openai import OpenAI# 加载一个长文本文件with open("example.txt", "r", encoding="utf-8") as f:
text = f.read()
user_input = text + "\n\n总结上述文本。"client = OpenAI(
api_key=os.getenv("YOUR_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen-turbo-latest",
messages=[
{'role': 'system', 'content': '你是一个有帮助的助手。'},
{'role': 'user', 'content': user_input},
],
)
print(completion.choices[0].message)Qwen2.5-Turbo模型性能
Qwen2.5-Turbo在各种基准测试中进行了评估,展示了其在处理长上下文和短上下文任务中的显著进步。
Passkey Retrieval
在1M-token Passkey Retrieval任务中,Qwen2.5-Turbo展示了其在超长上下文中识别详细信息的能力,准确率达到100%。
通过“Passkey Retrieval”测试Qwen2.5-Turbo
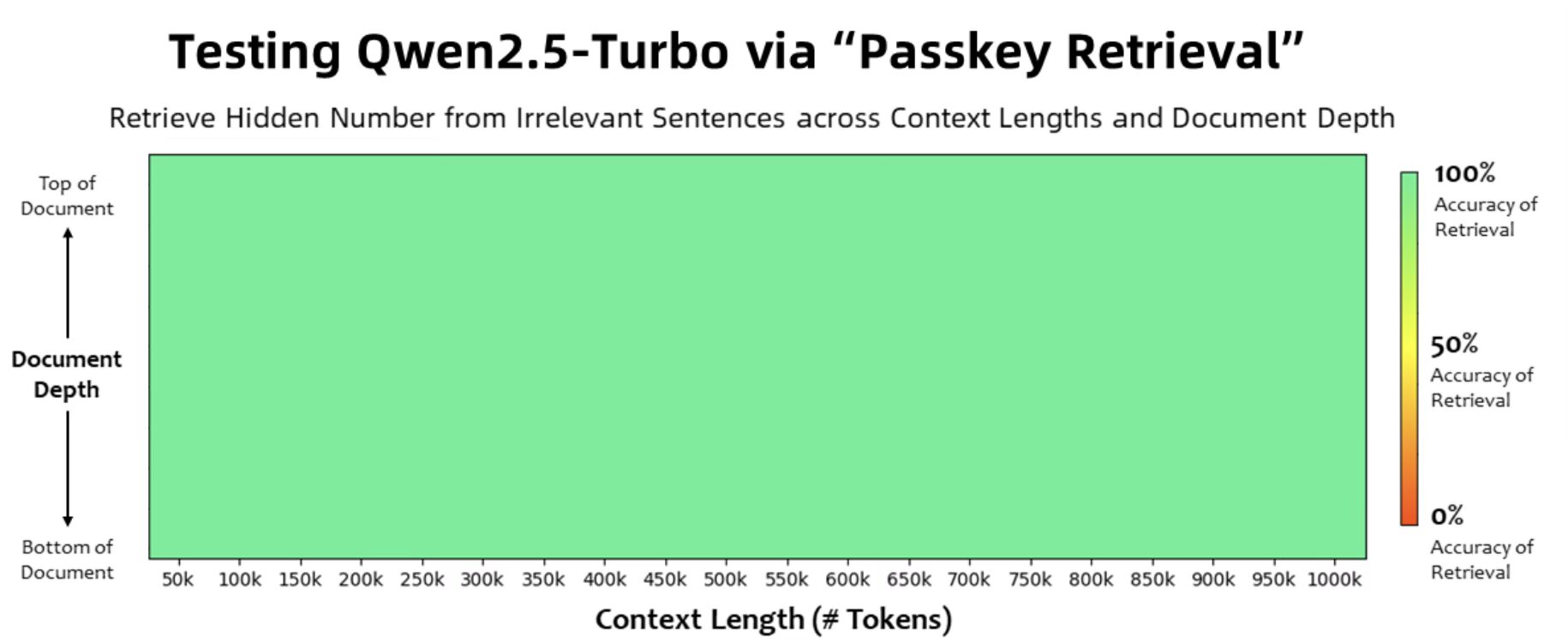
长文本理解
使用多个数据集评估模型的长上下文理解能力:
RULER:专注于在无关文本中寻找“针”、回答多个问题或分析词频等任务,该基准包含长达128K tokens的上下文。Qwen2.5-Turbo得分93.1,超过GPT-4o-mini和GPT-4。
LV-Eval:测试在长达256K tokens的上下文中理解大量证据片段的能力。调整后的指标防止了假阴性,确保了公平评估。
LongBench-Chat:评估需要长达100K tokens上下文任务的人类偏好对齐。
在这些测试中,Qwen2.5-Turbo始终超越GPT-4o-mini,处理超过128K tokens的任务,展示了其在长上下文理解中的优势。
短文本任务
与许多牺牲短文本性能的扩展上下文模型不同,Qwen2.5-Turbo在较短输入上保持了强劲的结果。其基准显示,它在其他1M-token模型中表现优异,并支持比GPT-4o-mini和Qwen2.5-14B-Instruct多8倍的上下文长度。
推理速度
Qwen2.5-Turbo利用稀疏注意力机制优化推理速度:
对于1M tokens的输入,稀疏注意力将计算压缩约12.5倍,在各种硬件配置下实现了3.2倍到4.3倍的加速。
1M-token序列的首个token生成时间(TTFT)从4.9分钟缩短至仅68秒,显著提高了效率。
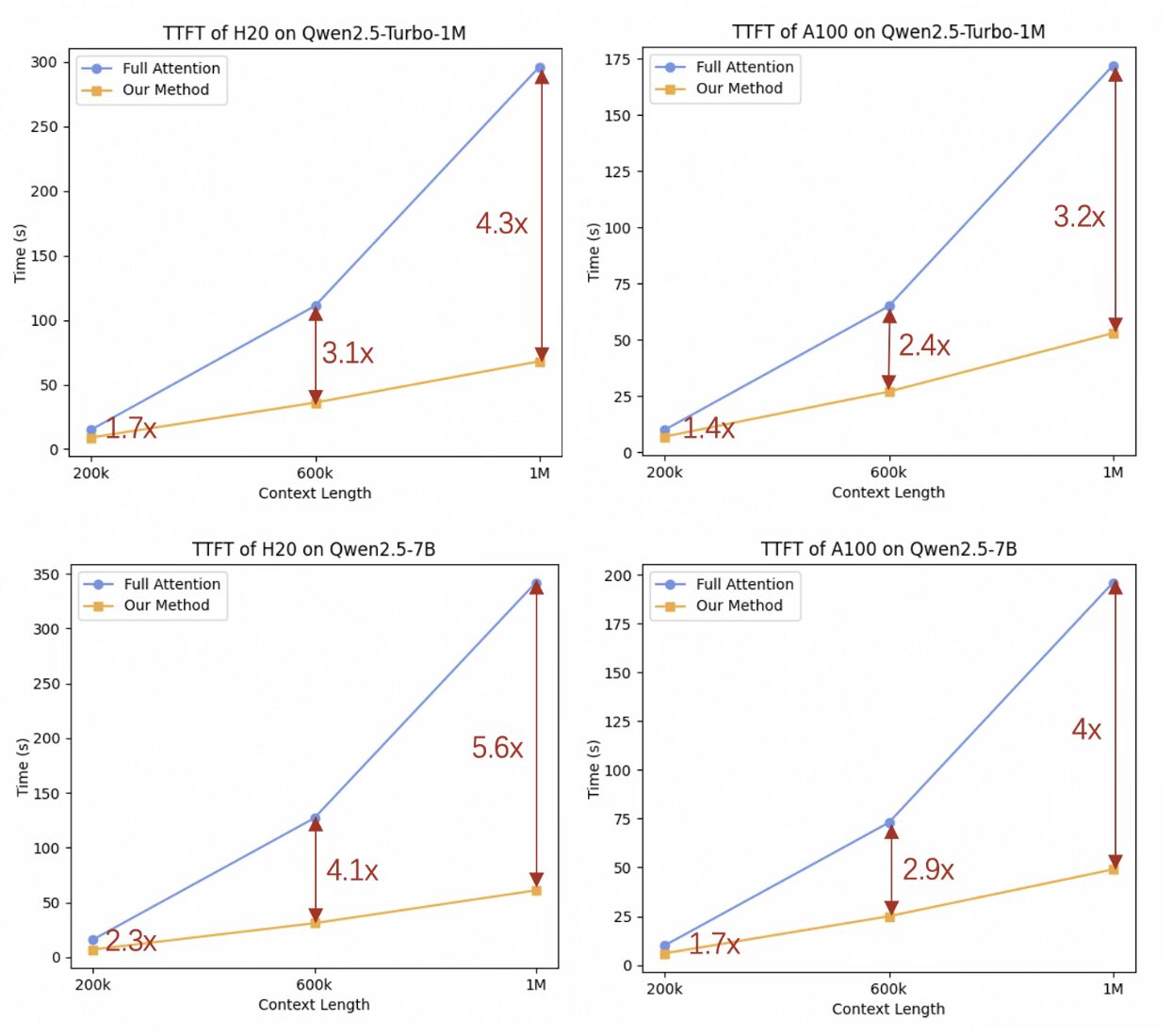
推理速度
展望未来
Qwen2.5-Turbo扩展到支持1M-token上下文是一个重要里程碑,但仍面临挑战。尽管模型在许多基准测试中表现出色,仍有改进空间:
长序列任务:在实际场景中的性能可能不够稳定。
推理成本:更大的模型需要优化以降低计算成本。
团队致力于通过改进长序列的人类偏好对齐、增强推理效率和探索更大、更强大的长上下文模型来应对这些挑战。敬请期待Qwen长上下文系列的下一步进展!
苏州白鸽云信息技术有限公司在利用人工智能和机器学习转变业务操作方面处于前沿。推出企业知识问答机器人标志着我们在致力于提供推动效率和增长的创新解决方案方面的重大进展。
更多信息,请联系:
苏州白鸽云信息技术有限公司
电子邮件:webmaster@baige.cloud
电话:+86-512-87699255
苏州白鸽云信息技术有限公司是一家领先的技术提供商,致力于推动包括出版在内的各个行业的数字化转型。
上一篇:无
